Dependency injection
MuPRO PREDICT
PREDICT = PREcipitation + DIffusion + reaCTion 是 MuPRO 开发的新一代针对相变、扩散、化学反应的相场模型,它的一大重要进步在于可以处理 line compound/stoichiometric compound。
几个演化阶段
原始版本是吉彦舟博士的 Fortran 代码。 由于很多功能与 MuPRO PhaseField SDK 中重合,例如傅里叶变换、生成 bmp 图片、求解弹性等,所以第一步是剔除重复的部分并跟 SDK 整合。我称下图为阶段一:
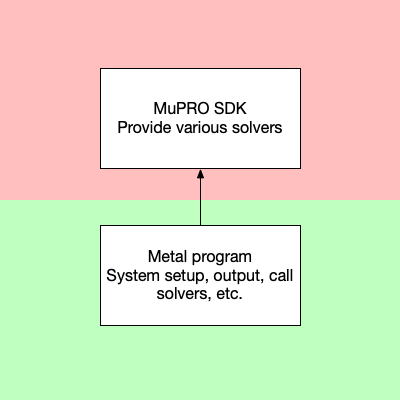
图中红色是闭源代码,绿色是开源代码。
至此,跟别的 MuPRO 主程序做法都是一样的,而 PREDICT 有一个特别的地方在于, 我们跟 Computherm LLC 合作,准备把它做成一个 Pandat 的插件,这样我们可以利用 Pandat 的热力学数据库, 而 Pandat 可以利用我们独特的相场模型。
为了能够同时得到 MuPRO PREDICT 的主程序和插件两个产品,并且实现代码最大程度的重复利用, 我很自然的决定把主要逻辑提取出来作为一个核心部分(作为一个函数库), 然后在主程序和插件中只是输入输出有不同的方式, 而具体计算的部分都是简单地调用核心提供的函数走完整个计算流程。我称下图为阶段二:
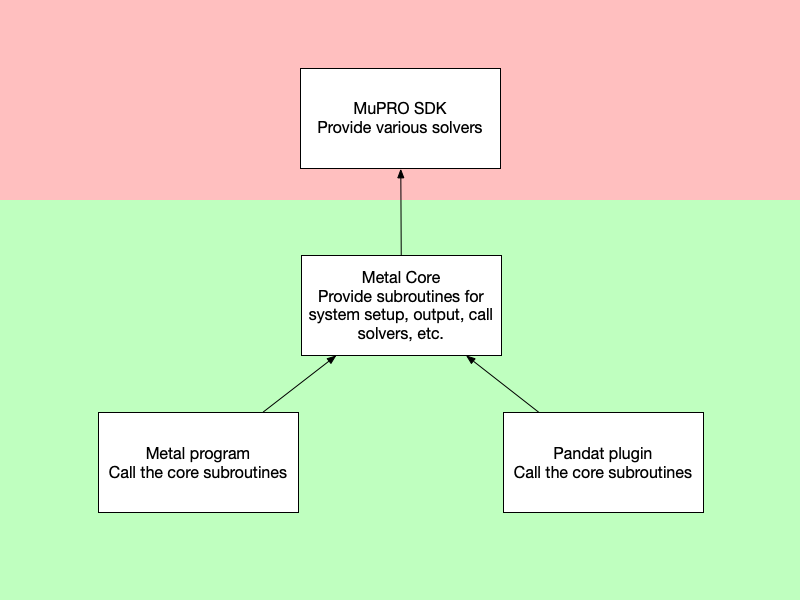
但这时我发现一个问题,也就是主程序和插件二者并不一定所有计算逻辑都完全一样, 尤其当我们想充分利用 Pandat 在热力学数据库上的优势的时候,至少在如何获取热力学数据这一点上二者是不同的。 对于主程序来说,用户直接在某个函数中定义了热力学函数,使用的时候调用这个用户定义的函数即可。 对于插件来说,我们需要用 Pandat 提供的函数从某个热力学数据库中提取需要的数据, 所以使用的时候需要调用 Pandat 的某个函数。 可见,在如何使用热力学函数这个核心逻辑上,主程序和插件使用的函数是不同的。
所以主程序和插件与核心部分的关系并不是简单的调用关系, 而是核心部分需要调用主程序和插件中各自的热力学函数完成能量和驱动力的计算, 然后主程序和插件需要调用核心部分的各个函数完成整个计算流程。我称下图为阶段三:
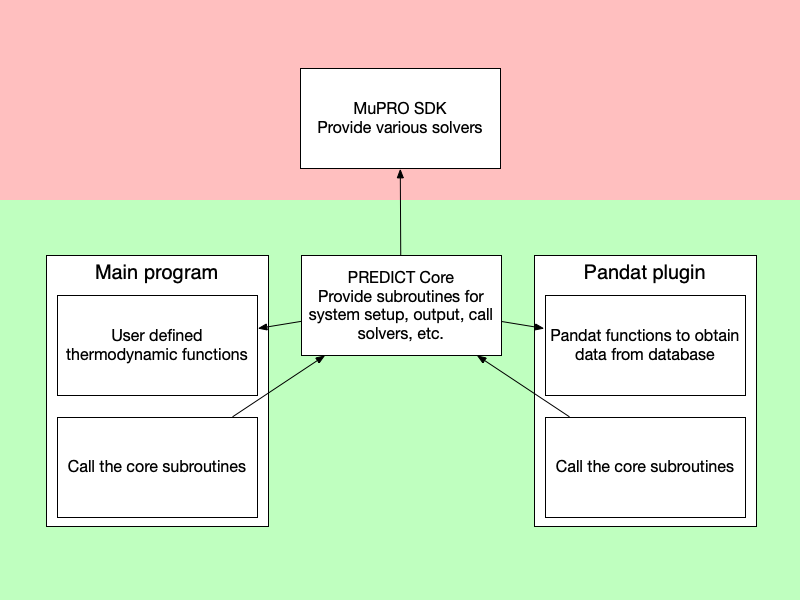
于是乎,现在的问题就是如何实现这个主程序、插件和核心的程序。
当前核心需求
总结一下我们现在的条件和需求:
- 主程序和核心部分都是 Fortran,而插件部分是 C++
- 现在代码状态是处在阶段二,主程序和插件使用了相同的热力学函数,我们想要让插件使用 Pandat 的数据库
- 最大程度重复利用代码,核心部分要能够根据使用者的不同调用不同的热力学函数(实现阶段三)
- 需要用尽量少的改动实现阶段三
方案一:dependency injection
看到这个需求我的第一反应就是可以用 dependency injection。 先来简单介绍一下 dependency injection 的概念,我们考虑以下这个问题怎么解决:
假如 client 使用了(依赖)service A,这就意味着 client 必须要在编译的时候能够找到 service A 但是现实中 service A 有很多功能相近的替代服务 B、C、D…。client 在定义的时候,不可能知道 所有可能得替代服务,这种情况下如何实现让 client 能够在编译的时候不需要知道 service A、B、C、D 的存在,而在使用的时候再被告知使用哪个 service。
要解决这个问题就使用 dependency injection,也就是我们 client 依赖的 service 是在具体用的时候才被选择的, 所谓 injection 就是把依赖的 service 注入到 client 中去。
具体实现如下:
- 先根据 client 的需求,定义一个 service 接口,也就是任何想被 client 用的 service 都需要符合这个接口
- 把 client 中所有 service A 都换成 service 接口,然后在 client 里要有某种机制允许传入具体的 service,常见的方法有以下几个
- constructor,也就是在生成 client 的时候就把 service 的选择定义在 constructor 中
- property setter,也就是具体 service 作为 client 的一个 property,专门用一个 setter 函数来定义 client 中的 service 类型
- method,也就是直接把 service 类型当做 client 中某个函数的参数传入并只在该函数中使用。 使用了 dependency injection 牺牲了程序的直白性,带来了极大的可拓展性
回到 PREDICT 的设计,可以看到核心部分就是 client,主程序和插件的热力学函数部分就是两个 service, 不过由于我们主要编程语言是 Fortran,并不是很适合用来实现面向对象的 dependency injection 的设计, 所以如果要用 dependency injection,在不大改程序的前提下,我想只能在核心部分中定义热力学函数的函数指针, 再提供一个这些函数指针的 setter 函数,这样主程序或是插件可以通过 setter 函数来设置函数指针具体指向的函数,如下图所示:

这样核心部分使用的函数指针就会根据主程序和插件的不同,去调用不同的热力学函数了。 看起来,在 PREDICT 中使用类 dependency injection 的做法并不复杂, 也比较好的保持了我们核心部分作为函数库的独立性,提供了切换热力学函数的可拓展性。
方案二:从编译上解决
但反过来想一想,我们其实并不需要可拓展性,因为大概永远都只会有主程序和 Pandat 插件这两种使用的情况。而且我们的问题跟一般的 dependency injection 又不太一样,一般的用法可能是 client 是在一个函数库中,各个 service 又有自己的函数库,而我们的主程序和插件本质上是两个程序,不可能在同一个程序同时用到主程序和插件。
所以实现我们需求的最简单做法大概就是不要把核心部分编译成一个函数库,而是在编译主程序和插件的时候把核心部分包括在各自的项目中一起编译。我们只需要根据核心部分使用热力学函数的规则,在主程序和插件中各自定义符合参数传递的函数就够了,由于主程序和插件是两个编译的项目,所以用相同的函数名并不会冲突,如下图:

思考与总结
在学习面向对象的编程过程中,我就学过 dependency injection 很多次, 不过这是第一次在自己的项目中认真考虑是否要使用这种设计模式。 在整个 PREDICT 框架的改进过程中通过一两天,仔细思考 dependency injection 的实现和优劣, 我最终根据项目的特点发现了比 dependency injection 更简单的解决方案。 不过我相信在未来的项目,比如 OpenCAXPlus 中的 FENGsim 一定有机会使用到 dependency injection 的设计。